

自从 9 月初开始明月就发现【玉满斋】好不容易得来的百度子链、Logo、官网标识甚至首页都在百度搜索结果里消失了,搜索品牌词“玉满斋”都是显示“www.主域名.com/ygs/”文章分类网址,主域名彻底的找不到了,辛苦几年的成果瞬间都没有了,真的是“晴天霹雳”呀!
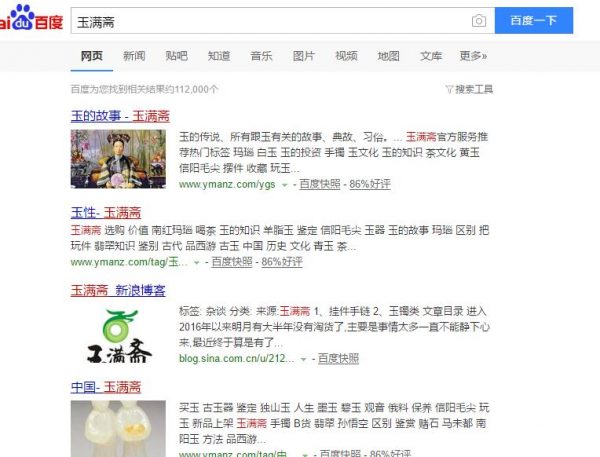
搜索“玉满斋”连首页都没有了!
本来以为是百度算法调整的暂时性问题,开始的时候一直没有重视,半个多月都过去了问题依然没有好转的迹象。这时,我才感觉应该是出问题了,于是马上开始着手自己排查问题了,经过几天的分析后发现主要是出现了一下几点问题:
- 恶意镜像泛滥严重。
- 因疏忽删除了 robots.txt,而主题已经不支持“www.主域名.com/page/”的链接形式,收录了一大量“www.主域名.com/page/”的无效链接,这些链接都是指向“www.主域名.com”的。
- 主机因为配置不当造成稳定性下降,经常宕机,百度站长平台收录抓取报错频繁。
发现问题就马上开始采取应对措施:

至今发现的恶意镜像和跳转的域名!
恶意镜像的处理
恶意镜像最近泛滥成灾,发现很多博客都遇到这个问题,特别是在百度的搜索结果里特别的多,谷歌里这种问题几乎没有,看来百度在这方面的技术有待提高呀,至于这种恶意镜像实现原理据说是“反向代理”实现的,成本非常的低,防范措施网上倒是不少,但经过我近一周的测试,有用的很少很少,最后就找到一个自动跳转会指定域名代码有点效果以及一个通过判断 UA 信息来防止恶意镜像的代码。经过近十天的使用感觉也是治标不治本的方法,没有办法了只能采用最笨的方法,那就是向百度反馈和举报了。
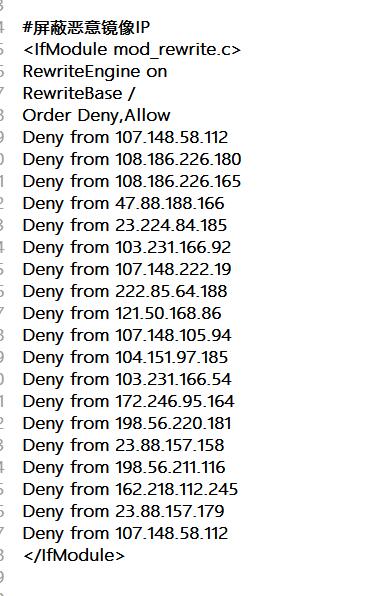
另外除了举报和反馈外,还通过在百度里搜索网站首页标题可以在结果里找到恶意镜像的网址域名并记录下来,通过 ping 解析获得 IP,通过.htacess 来屏蔽这个 IP,这个工作要经常性的去做,日积月累的可以有效的遏制恶意镜像的。
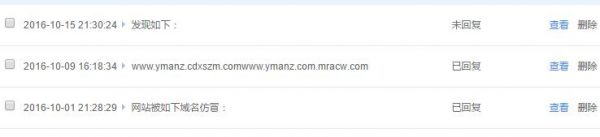
百度站长平台里的反馈
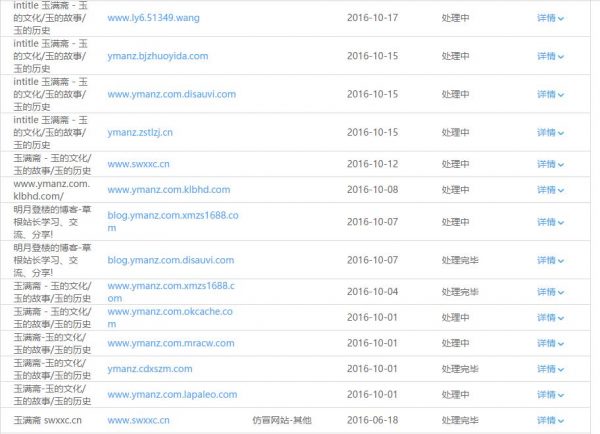
百度搜索结果的“举报”
用了一周时间采集图片截图证据后分别举报和反馈,有些已经回复并告之已处理,有些还在等待结果中,但是百度搜索结果里的恶意镜像已经承减缓趋势了。
用到的代码如下(以下代码都是添加到主题的Function.php里的):
通过UA信息防止镜像
- if(!is_admin()) {
- add_action(‘init’, ‘deny_mirrored_request’, 0);
- }
- function deny_mirrored_request()
- {
- //获取 UA 信息
- $ua = $_SERVER[‘HTTP_USER_AGENT’];
- //将恶意 USER_AGENT 存入数组
- $now_ua = array(‘PHP’,’FeedDemon ‘,’BOT/0.1 (BOT for JCE)’,’CrawlDaddy ‘,’Java’,’Feedly’,’UniversalFeedParser’,’ApacheBench’,’Swiftbot’,’ZmEu’,’Indy Library’,’oBot’,’jaunty’,’YandexBot’,’AhrefsBot’,’MJ12bot’,’WinHttp’,’EasouSpider’,’HttpClient’,’Microsoft URL Control’,’YYSpider’,’jaunty’,’Python-urllib’,’lightDeckReports Bot’);
- //禁止空 USER_AGENT,dedecms 等主流采集程序都是空 USER_AGENT,部分 sql 注入工具也是空 USER_AGENT
- if(!$ua) {
- header(“Content-type: text/html; charset=utf-8”);
- wp_die(‘郑重警告:请勿采集本站,因为采集的站长木有小 JJ!’);
- }else{
- foreach($now_ua as $value )
- //判断是否是数组中存在的 UA
- if(eregi($value,$ua)) {
- header(“Content-type: text/html; charset=utf-8”);
- wp_die(‘郑重警告:请勿采集本站,因为采集的站长木有小 JJ!’);
- }
- }
- }
非主域名的访问自动跳转至指定域名
(注:记得要将代码内的“主域名”修改为自己的域名哦)
- add_action(‘wp_footer’,’deny_mirrored_websites’);
- function deny_mirrored_websites(){
- $currentDomain = ‘www.” + “主域名.” + “com’;
- echo ‘<img style=“display:none” src=” “ onerror=\’var str1=“‘.$currentDomain.'”;str2=“docu”+“ment.loca”+“tion.host”;str3=eval(str2);if( str1!=str3 ){ do_action = “loca” + “tion.” + “href = loca” + “tion.href” + “.rep” + “lace(docu” +“ment”+“.loca”+“tion.ho”+“st,” + “\”‘ . $currentDomain .’\”” + “)”;eval(do_action) }\’ />’;
- }
总结分析:
目前看来,举报反馈还是有效果的,两个代码也起到了一些作用,毕竟恶意镜像是为了借助镜像网站的流量来达到不可告人的目的的,直接跳转回指定域名对其反制还是“有的放矢”的。
robots.txt的启用
因为疏忽删除了robots.txt,现在看来这是一个不可原谅的疏忽呀!在 robots.txt 加上“Disallow: /page/”禁止搜索引擎抓取,并且在百度站长平台里提交“www.主域名.com/page/”死链来去除搜索结果里的这些无用链接,经过 3-5 天后搜索结果里没有这些死链了。
总结分析:
robots.txt 文档还是非常重要的,绝对是不能没有的,特别是国内网站,因为百度自身技术的不成熟对于链接的分析和辨析能力还是依赖人工的多一些,所以 robots.txt 一定要用好了,并且 robots.txt 的要随着网站的连接结构调整而进行相应的配置,这次首页品牌词权重的丢失估计跟 robots.txt 有很大的关系,失效的“www.主域名.com/page/”应该是分化了首页链接的权重的。
主机的稳定性很关键
稳定主机基本上是个站点优化里老生常谈的问题了,但是对于一个喜爱折腾的草根站长来说,有时候真的是“No do!No die!”呀,不折腾就不会有那么多的问题,前一阵子为了好玩在侧边栏里加入了“百度打赏”的组件,没有想到造成了评论链接一直报“连接超时”的提示框,废了很大的功夫才找到是“百度打赏”的一段代码链接死链造成的。又因为折腾缓存插件缓存了全站的 JS 文档,造成网站评论提交后出现“404 页面”都半个多月了才发现,囧呀!
总结分析:
能不瞎折腾就不瞎折腾,要折腾也尽量在本地先行测试好了在折腾,有些怪异的故障都是“折腾”造成的。
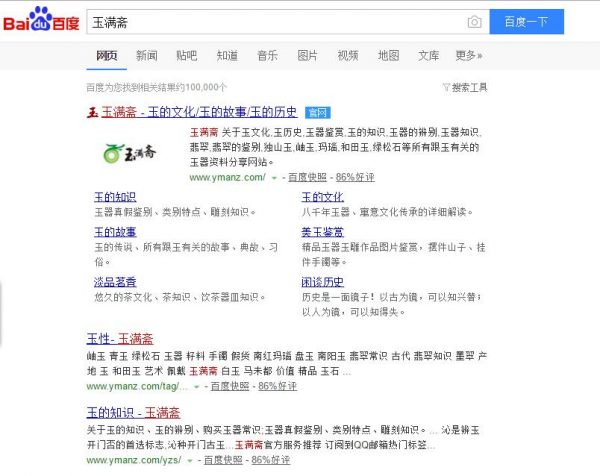
经过上述的这些调整后,终于就在前天我的品牌词权重恢复了,首页也回来了,所有消失的都回来了,唉!累死我了都!想想都是自己作的呀!









 桂公网安备 45010502000016号
桂公网安备 45010502000016号