

今天无意间发现我的两个站点访问速度都非常缓慢,登录阿里云后台看了 ECS 服务器才发现 CUP 的使用率经常达到 99-100%,看了日志才发现 yisouspider(一搜蜘蛛,现在应该是属于神马的)蜘蛛正在疯狂爬行,就算是我在 robots.txt 设置了禁止爬行的路径也被爬行了。如果是凌晨爬行就不说了,竟然是在大白天疯狂爬行,分分钟可以搞瘫我们的站点,度娘一下发现有很多人都在吐槽这个 yisouspider,最终的解决方案就是直接禁止 yisouspider 的爬行和访问。
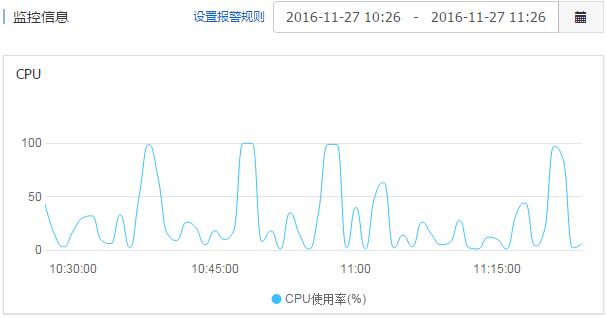
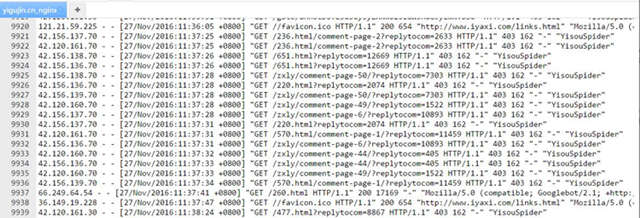
yisouspider 爬行 robots 文件禁止的路径
UC社区神马搜索中给出的解释:
robots.txt 是搜索引擎访问网站时要访问的第一个文件,以确定哪些网页是允许或禁止抓取的。yisouspider遵守robots.txt协议。如您希望完全禁止神马访问或对部分目录禁止访问,您可以通过 robots.txt 文件来设置内容,限定 yisouspider 的访问权限。
如果您开通了 CNZZ 云推荐服务,协议中默认支持 yisouspider 抓取,会忽略 robots.tx 文件协议的限制。
限定Yisouspider访问权限的robots协议写法
robots.txt 必须放在网站根目录下,且文件名要小写。
具体写法:
1) 完全禁止 yisouspider 抓取:
- User-agent: yisouspider
- Disallow: /
2) 禁止 yisouspider 抓取指定目录
- User-agent: yisouspider
- Disallow: /update
- Disallow: /history
禁止抓取 update、history 目录下网页
不过我也懒得折腾这个针对 yisouspider 的 robots 协议,我还是直接在 nginx 里面禁止 yisouspider 来得更有效果。
Nginx屏蔽爬虫yisouspider访问站点方法:
进入到 nginx 安装目录下的 conf 目录,将如下代码保存为 agent_deny.conf
- #禁止 Scrapy 等工具的抓取
- if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
- return 403;
- }
- #禁止指定 UA 及 UA 为空的访问
- if ($http_user_agent ~ “yisouspider|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$” ) {
- return 403;
- }
- #禁止非 GET|HEAD|POST 方式的抓取
- if ($request_method !~ ^(GET|HEAD|POST)$) {
- return 403;
- }
然后,在网站相关配置中的
- location / {
- try_files $uri $uri/ /index.php?$args;
下方插入如下代码:
- include agent_deny.conf;
保存后,执行如下命令,平滑重启 nginx 即可:
- /usr/local/nginx/sbin/nginx -s reload
懿古今和 boke112 导航站点就是使用这个方法成功屏蔽爬虫 yisouspider 访问。设置好之后,我的 ECS 服务器 CPU 的使用率立马就降下来了。
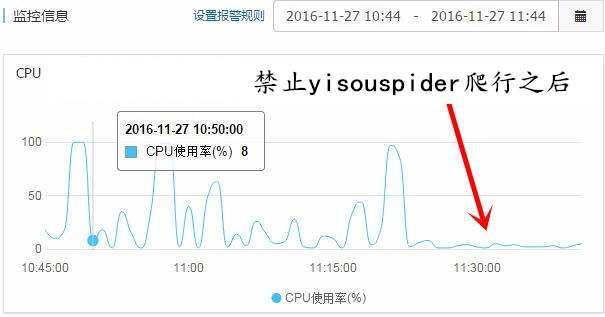
根据百度统计给出的数据,我的站点来自神马搜索的不多,所以权衡之下只能禁止 yisouspider 蜘蛛爬行了,要不然我的站点经常被它搞瘫了就得不偿失了。如果你的服务器比较给力,不会被搞瘫的话,就没必要禁止它了。
PS:请允许我用小心之心揣测,以前使用阿里云免费虚拟主机每个月都会出现资源耗尽,最大的问题很有可能就会被 yisouspider 蜘蛛爬行导致的。
Apache屏蔽爬虫yisouspider访问站点方法:
1、通过修改 .htaccess 文件
修改网站目录下的.htaccess,添加如下代码即可(2 种代码任选):
可用代码 (1):
- RewriteEngine On
- RewriteCond %{HTTP_USER_AGENT} (^$|yisouspider|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) [NC]
- RewriteRule ^(.*)$ – [F]
可用代码 (2):
- SetEnvIfNoCase ^User-Agent$ .*(yisouspider|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) BADBOT
- Order Allow,Deny
- Allow from all
- Deny from env=BADBOT
2、通过修改 httpd.conf 配置文件
找到如下类似位置,根据以下代码 新增 / 修改,然后重启 Apache 即可:
- DocumentRoot /home/wwwroot/xxx
- <Directory “/home/wwwroot/xxx”>
- SetEnvIfNoCase User-Agent “.*(yisouspider|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)” BADBOT
- Order allow,deny
- Allow from all
- deny from env=BADBOT
- </Directory>
PHP代码屏蔽爬虫yisouspider访问站点方法:
将如下方法放到贴到网站入口文件 index.php 中的第一个 <?php 之后即可:
- //获取 UA 信息
- $ua = $_SERVER[‘HTTP_USER_AGENT’];
- //将恶意 USER_AGENT 存入数组
- $now_ua = array(‘yisouspider’,’FeedDemon ‘,’BOT/0.1 (BOT for JCE)’,’CrawlDaddy ‘,’Java’,’Feedly’,’UniversalFeedParser’,’ApacheBench’,’Swiftbot’,’ZmEu’,’Indy Library’,’oBot’,’jaunty’,’YandexBot’,’AhrefsBot’,’MJ12bot’,’WinHttp’,’EasouSpider’,’HttpClient’,’Microsoft URL Control’,’YYSpider’,’jaunty’,’Python-urllib’,’lightDeckReports Bot’);
- //禁止空 USER_AGENT,dedecms 等主流采集程序都是空 USER_AGENT,部分 sql 注入工具也是空 USER_AGENT
- if(!$ua) {
- header(“Content-type: text/html; charset=utf-8”);
- die(‘请勿采集本站,因为采集的站长木有小 JJ!’);
- }else{
- foreach($now_ua as $value )
- //判断是否是数组中存在的 UA
- if(eregi($value,$ua)) {
- header(“Content-type: text/html; charset=utf-8”);
- die(‘请勿采集本站,因为采集的站长木有小 JJ!’);
- }
- }
附录:UA收集
下面是网络上常见的垃圾 UA 列表,仅供参考,同时也欢迎你来补充。
- yisouspider 一搜蜘蛛
- FeedDemon 内容采集
- BOT/0.1 (BOT for JCE) sql 注入
- CrawlDaddy sql 注入
- Java 内容采集
- Jullo 内容采集
- Feedly 内容采集
- UniversalFeedParser 内容采集
- ApacheBench cc 攻击器
- Swiftbot 无用爬虫
- YandexBot 无用爬虫
- AhrefsBot 无用爬虫
- YisouSpider 无用爬虫(已被 UC 神马搜索收购,此蜘蛛可以放开!)
- MJ12bot 无用爬虫
- ZmEu phpmyadmin 漏洞扫描
- WinHttp 采集 cc 攻击
- EasouSpider 无用爬虫
- HttpClient tcp 攻击
- Microsoft URL Control 扫描
- YYSpider 无用爬虫
- jaunty wordpress 爆破扫描器
- oBot 无用爬虫
- Python-urllib 内容采集
- Indy Library 扫描
- FlightDeckReports Bot 无用爬虫
- Linguee Bot 无用爬虫













 桂公网安备 45010502000016号
桂公网安备 45010502000016号