

很多 SEOer 并没有理解爬行、抓取、索引、收录这些概念到底指的是什么,区别在哪,noindex、nofollow、robots 文件的功能又是什么。对这些概念没有精准理解,处理大型网站结构,决定什么页面需要被抓取,什么需要被索引,哪些页面需要禁止抓取、索引等等情况时,就很难明白该怎么做。所以今天就把重点说说这些很基本但又很重要,而且又比较容易混淆的 SEO 概念。

爬行是什么?
爬行指的是搜索引擎蜘蛛从已知页面上解析出链接指向的 URL,然后沿着链接发现新页面(也就是链接指向的 URL)的过程。当然,蜘蛛并不是发现新 URL 马上就爬过去抓取新页面,而是把发现的 URL 存放到待抓地址库中,蜘蛛按照一定顺序从地址库中提取要抓取的 URL。
抓取是什么?
抓取是搜索引擎蜘蛛从待抓地址库中提取要抓的 URL,访问这个 URL,把读取的 HTML 代码存入数据库。蜘蛛的抓取就是像浏览器一样打开这个页面,和用户浏览器访问一样,也会在服务器原始日志中留下记录。
索引是什么?
索引指的是将一个 URL 的信息进行整理,存入数据库,也就是索引库,用户搜索时,搜索引擎从索引库中提取 URL 信息并排序展现出来。索引的英文是 index。索引库是用于搜索的,所以被索引的 URL 是可以被用户搜索到的,没有被索引的 URL 用户在搜索结果中是看不到的。
要注意的是,所谓“一个 URL 的信息“,并不限于蜘蛛从 URL 上抓取来的内容,还有来自其它来源的信息,如外部链接、链接的锚文字等。有的时候,索引库中关于这个 URL 的的信息,根本没有从这个 URL 抓取来的内容,但搜索引擎知道这个 URL 的存在,并且有一些其它信息。
收录是什么?
我个人觉得收录和索引没有区别。只不过收录是从搜索用户角度看的,搜索时能找到这个 URL,就是这个 URL 被收录了。从搜索引擎角度看,URL 被收录了,也就是这个 URL 的信息在索引库中存在。英文并没有收录这个词,和索引用的是同一个词 index。
Noindex 的作用是什么?
页面头信息中放上 meta noindex 标签是告诉搜索引擎不要索引这个 URL,也就是用户搜索时找不到这个 URL 的信息,这个 URL 不会返回在搜索结果列表中。
Noindex 不是告诉搜索引擎不要抓取这个 URL,实际上,noindex 要起作用,这个 URL 是必须先被抓取的,不然搜索引擎怎么看到页面 HTML 代码中有 noindex 标 签呢?
robots 文件的作用是什么?
Robots 文件是告诉搜索引擎,某些 URL 不要抓取。注意,这里说的是不要抓取,没说不要索引。和 noindex 是正相反的。
nofollow 的作用是什么?
给链接加上 nofollow 属性是告诉搜索引擎,不要沿着这个链接爬行,就当这个链接不存在。注意,nofollow 只是告诉蜘蛛不要爬这个链接,没有说不要抓取链接指向的 URL,也没有说不要索引链接指向的 URL,nofollow 既没禁止抓取,也没禁止索引。
没有被抓取的页面是可以被索引的
也就是说,蜘蛛没有访问和抓取这个页面(比如被 robots 文件禁止抓取),这个页面却有信息存在索引库中,用户搜索时还能看到。
比如,淘宝整个网站用 robots 文件禁止百度蜘蛛抓取,但没有用 noindex 禁止索引(如上面说的,禁止抓取后,就没办法禁止索引了,不抓取,就看不到 noindex 标签了),所以即使百度没有访问和抓取淘宝页面,但淘宝很多页面是被百度索引的,用户可以搜到的:
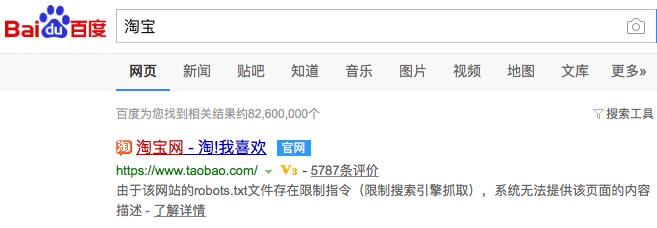
百度从网上那么多链接知道淘宝首页的存在,通过链接的锚文字也知道这个页面标题大概是淘宝之类的,当然更知道百度口碑里的评价数。所以即使百度蜘蛛没有抓取淘宝首页,用户还是能搜到,并且显示一些百度知道的信息。
要想百度不能返回淘宝首页该怎么办呢?取消 robots 文件的禁止抓取,页面上用 noindex 禁止索引。
被抓取的页面是可以不被索引的
最常见的就是上面说过的,页面头信息使用 noindex 禁止索引,页面被抓取,读到 noindex 后,不被索引,不会在搜索结果中返回。
还有可能是因为页面内容是抄袭、转载、低质量的,搜索引擎虽然抓取了页面,索引过程中检测出这些内容问题,被丢弃,没有被索引。所以页面没有被收录,通常要先检查原始日志,看看是否被抓取过,如果被抓取过,可能是内容质量问题,如果根本没被抓取,建议先看看网站结构是否有问题。
加了 nofollow 的链接目标页面可以被抓取和索引
前面说了,nofollow 既不禁止抓取,也不禁止索引。Nofollow 的作用是告诉蜘蛛不要跟着这个链接爬,就当这个链接不存在,但 nofollow 只对这个链接起作用,对别的链接没作用,这个链接加了 nofollow,不意味着别的地方就没有正常的指向这个 URL 的链接,只要别的地方出现了没加 nofollow 的链接,目标 URL 还是会被发现、抓取(假设没被 robotx 文件禁止)、索引(假设没加 noindex )。











 桂公网安备 45010502000016号
桂公网安备 45010502000016号