


只要是用 WordPress 的人或多或少都会装几个插件,可以用来丰富扩展 WordPress 的各种功能。围绕 WordPress 平台的插件和主题已经建立了一个独特的经济生态圈和开发者社区,养活了众多的 WordPress 相关的开发公司和开发者。各种强大的 WordPress 插件也层出不穷,有的甚至可以做出功能完善的网站,比如招聘网站、分类信息网站、电商网站、点评网站、培训网站等等,令我赞叹不已。

最近一直沉迷于研究 WordPress,仿佛事隔多年与初恋情人再续前缘一般陷入热恋。这几天突发奇想把 WordPress 上这么多眼花缭乱的插件都爬下来,看看能不能分析出一点有意思的东西来。
总体思路
官网插件的页面(点此直达打开)上列出了一共有 54,520 个插件。记得以前在官网上可以按各种分类浏览的,现在只有推荐的插件、收藏的插件、流行的插件几大类显示出来,其他的好像只能靠人肉搜索了,非常不方便。
那么首先第一步我们要知道去哪里可以找到所有的 WordPress 插件列表,搜了一圈发现 WordPress 的 svn 上有这个完整的列表(http://plugins.svn.wordpress.org/)。 这个网页(比较大,5M 多,慎点)比官网上的插件还要齐全,一共 7 万多个。现在有了完整列表就好办了。
接下来就是要获取插件的各种信息,比如作者、下载量、评分等等。这个可以去哪里获取呢?当然最傻的办法就是根据上面列表中的插件地址,把每个插件的网页 down 下来再提取,这也就是爬虫干的事。不过 WordPress.org 网站自身的 WordPress.org API 已经给开发者提供了非常方便强大的接口,可以获取到几乎所有 wordprss.org 上的主题、插件、新闻等相关的信息,也支持各种参数和查询。注意,这个和 WordPress 的 REST API 是两回事。基本上你可以理解成 Apple.com 的 API 和 iOS 的 API 之间的区别(虽然 apple.com 并没有什么 API)
比如本次需要插件的一些数据,那就可以使用关于插件描述的 API: https://api.wordpress.org/plugins/info/1.0/{slug}.json,slug 也就是每个插件唯一的地址,这个在刚才 svn 上已经可以获取到了。用这个 API 可以返回关于插件的 json 格式的各种详细信息,很全面,如下:
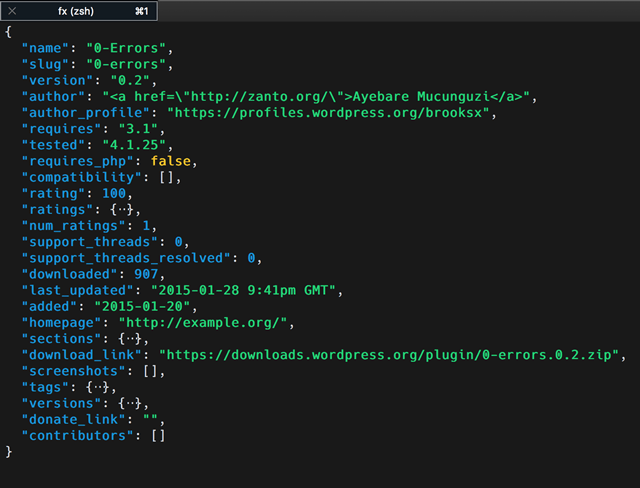
有了列表,有了返回格式,接下来就是要把这些信息给扒下来,其实就是重复遍历一遍就可以了,要么用著名 Python 的 Requests 库循环一圈,要么使用 Python 的爬虫框架 Scrapy,都是可以的。在存储爬取数据方面,本来打算用 scrapy 并且存入 mongodb 的,但是遇到的一个坑是 API 返回的 json 对象里 version 有的 key 是带小数点的,比如”0.1”这种是无法直接存入 mongodb 的,会报错说 key 不能包含点.,具体见下图:

不用就不用呗,改 key 才蛋疼了。所以这可以祭出另外一个厉害的 python 库 jsonline 了,它可以以 jsonl 文件的形式一行存储一条 json,读写速度也很快。最后爬完所有数据的这个文件有 341M 之大!
最后,有了数据就可以做一些有意思的数据分析了,这一步主要会用到的就是一些常见的 Python 的数据分析工具和图表工具,pandas、numpy、seaborn 等。根据上面的返回信息可以看出,能够分析的维度也是很多的,比如哪些作者开发的插件最多、哪些插件的下载量最多、哪些类别的插件最多、哪些国家的开发者最多、每年的插件增长量等等,甚至更进一步可以把所有插件的 zip 文件下载下来用 AI 做一些深入的代码分析等等,想想还是挺有意思的,本文的目标也就是提供一种思路和方法,希望能抛砖引玉。
下面进开始进入代码的世界,用 Python 爬取 WordPress 官网所有插件吧。
爬取数据准备工作
要爬数据一般第一步是要确认爬虫的入口网页,也就是从哪里开始爬,沿着入口网页找到下一个 URL,找-爬-找,不断循环重复直到结束。一般来说入口网页的分析都可以在 scrapy 内部进行处理,如果事先就已经可以明确知道所有要请求的网页地址,那么也可以直接把 url 列表扔进 scrpay 里,让它顺着列表一直爬爬爬就行了。
本次为了说的清晰一点,爬虫部分不用再次解释,所以分步进行,先把要爬的所有 url 准备好等下可以直接使用。之前说过了,WordPress 所有的插件名称列表(http://plugins.svn.wordpress.org/)在这里可以找到,这网页是一个非常简单的静态网页,就是一个巨大的 ul 列表,每一个 li 就是一个插件名字:
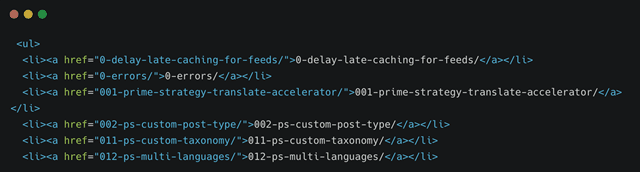
plugins.svn.wordpress.org 的网页源代码
这里的 href 就是插件的 slug,是 wordpress.org 用来确定插件的唯一标示。解析这种 html 对 Python 来说简直是小菜一碟,比如最常用的 BeautifulSoup 或者 lxmp,这次决定尝试一个比较新的库,Requests-HTML: HTML Parsing for Humans,这也是开发出 Requests 库的大神 kennethreitz 的又一力作,用于解析 HTML 文档的简直不要太爽了。
slug 得到后,按照 API 的 url 格式地址组合起来,全部写入一个文件中就可以了。
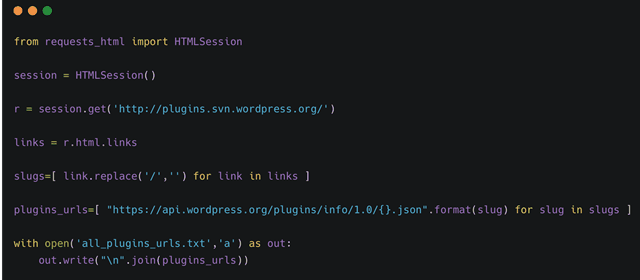
python 库 requests_html 的用法
作为对比,可以看下用 BeautifulSoup 的方法:

python 库 BeautifulSoup 的用法
就这么一个简单对比还是比较明显的,简单明了。最终,这一步的输出结果就是这个 all_plugins_urls.txt 文件了,总共有 79223 个插件。
有了这个列表,其实下面的 Scrapy 步骤其实完全可以不用,直接拿 wget 都可以全部简单粗暴的怼下来 7 万个 json 文件:
wget -i all_plugins_urls.txt或者用 requests 简单的遍历请求一下就完事了,就可以得到所有插件的数据,进而可以直接进入数据分析阶段了。为了作为演示吧,也算作是一个简单的 scrapy 的介绍,对于没有接触过 scrapy 的朋友来说,可以是一个很初步的入门介绍。
安装 scrapy
这一步最简单的方式就是 pip 安装
pip install Scrapy
scarpy -V # 验证一下新建项目 (Project):新建一个新的爬虫项目
scrapy 提供了完善的命令工具可以方便的进行各种爬虫相关的操作。一般来说,使用 scrapy 的第一件事就是创建你的 Scrapy 项目。我的习惯是首先新建一个文件夹(用要爬的网站来命名,这样可以方便的区分不同网站的爬虫项目)作为总的工作区, 然后进入这个文件夹里新建一个 scrapy 的项目,项目的名字叫做 scrap_wp_plugins,可以改成你想要的名字
mkdir ~/workplace/wordpress.org-spider
cd ~/workplace/wordpress.org-spider
scrapy startproject scrap_wp_plugins这样就会自动创建好类似如下的文件结构:
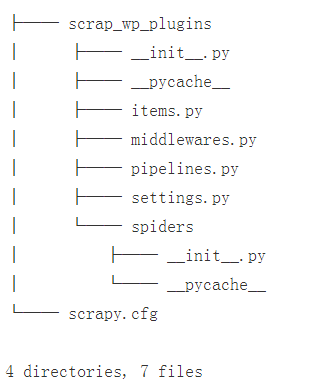
对我们这个需求来说,除了 settings.py 需要做一点点修改,其余文件都先不用管它,在这个简单的不能再简单的项目里都用不到。
目前只是一个空架子,啥也干不了,因为还没有爬虫文件,你可以完全纯手写,也可以用模板来生成一个。我们就用 scrapy 的命令行自动生成一个爬虫,语法格式是这样:
Syntax: scrapy genspider [-t template] <name> <domain>其中:
- template:是要使用的爬虫的模板,默认的就是用最基本的一个。
- name:就是爬虫的名字,这个可以随便取,等下要开始爬的时候会用到这个名字。好比给你的小蜘蛛取名叫“春十三”,那么在召唤它的时候你就可以大喊一声:“上吧!我的春十三!”
- domain:是爬虫运行时允许的域名,好比说:“上吧!我的春十三!只沿着这条路线上!”
所以执行如下命令即可:
cd scrap_wp_plugins
scrapy genspider plugins_spider wordpress.org这样就会在 spiders 文件夹下生出一个叫 plugins_spider.py 的爬虫文件,也就是在这里面可以填充一些爬取逻辑和内容解析。
制作爬虫(Spider):制作爬虫开始爬取网页
首先我们打开 scrap_wp_plugins/plugins_spider.py 看下里面的内容:

Created spider ‘plugins_spider’ using template ‘basic’ in module: scrap_wp_plugins.spiders.plugins_spider可以看出这就是一个最简单 scrapy 的 Spider 的类而已,自动填入了上一步用来创建爬虫时的一些参数。
- name:爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字,就是上一步的命令行里写的
- start_urls:爬虫开始爬的一个 URL 列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些 URLS 开始。其他 URL 将会从这些起始 URL 中继承性生成。具体来说,在准备工作那一部分,我们已经得到了一个 urls 的列表文件 txt,现在只需要把这个文件读取进来就好了。
- parse():爬虫的方法,调用时候传入从每一个 URL 传回的 Response 对象作为参数,response 将会是 parse 方法的唯一的一个参数,这个方法负责解析返回的数据、匹配抓取的数据(解析为 item)并跟踪更多的 URL。在本项目中,因为返回的是 json,不需要解析任何 html,这里为了省事我就直接把 json 整个存储起来已备后面数据分析的时候再选择需要的字段,当然你也可以根据需要选择过滤掉不需要的 json 字段。
所以,我们的第一个爬虫就呼之欲出了!请看代码,麻雀虽小五脏俱全

a simple spider will crawl all plugins from wordpress.org
运行爬虫
改完上面的爬虫代码,现在就可以让爬虫跑起来了,“上吧!比卡丘!”
scrapy crawl plugins_spider哦嚯。。。
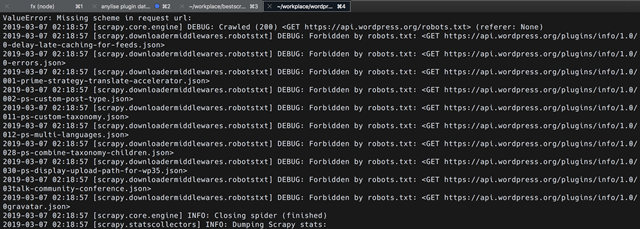
Forbidden by robots.txt
意外发生了。。。啥也没爬下来??Don’t Panic !别慌,仔细看下报错信息,原来是 https://api.wordpress.org/robots.txt 规定了不允许爬虫,而 scrapy 默认设置里是遵守 robot 协议的,所以简单绕过就行了,打开 setttings.py, 找到下面这行,把 True 改为 False,意思是:“爱咋咋地,老子不屌你的 robots.txt ”
# Obey robots.txt rules
ROBOTSTXT_OBEY = True再次运行现在就可以愉快的爬取了。还有一点温馨提示,如果爬取网址数量比较多,不想中途因为断网或者其他什么鬼知道的意外中断,导致下次又要重新来过,可以加上 scrapy 的执行日志来保存爬虫状态,下次就会从中断处开始继续爬取
scrapy crawl plugins_spider -s JOBDIR=spiderlog --logfile log.out &这样就可以安心的去睡个觉,一早起来就能看到热呼呼新鲜出路的 WordPress 所有的插件信息了。
未完待续
本想放在一篇写的,没想到光爬信息这点东西写了这么多写到这么晚……可能东拉西扯废话太多了,下一篇继续再写关于数据分析的科普文吧。









 桂公网安备 45010502000016号
桂公网安备 45010502000016号