

前面boke112百科跟大家分享了什么是阿里云E-MapReduce(EMR)及免费使用的情况,今天继续跟大家分享阿里云E-MapReduce的产品优势、产品功能和适用的使用场景。
阿里云E-MapReduce(简称EMR)
ERM阿里云云原生数据湖的核心计算引擎,全面支持Hadoop、Spark、HBase、Hive、Flink等大数据组件,为客户提供企业级开源大数据平台服务。通过有效弹性伸缩和数据分层存储机制,相较于传统HDFS固定集群方式,可节省50%以上的费用,同时支持创建抢占式实例,相比按量付费的购买方式,可节省50%~80%的费用。
阿里云E-MapReduce的产品优势
1、开源生态:提供高性能、稳定版本Hadoop、Spark、Hive、Flink、Kafka、HBase、Presto、Impala、Hudi等开源大数据组件,客户可根据场景灵活搭配使用。
2、引擎优化:多引擎性能优化,如Spark SQL较开源版本提升6倍。采用JindoFS+OSS,保证数据可靠性基础上,性能大幅提升。
3、便捷运维:在阿里云控制台和OpenAPI方便地对集群、节点和服务进行监控和运维操作。助您大幅提升运维工作效率,让数据工程师更专注于业务开发。
4、节约成本:集群资源可自动按需匹配,您只需要按实际使用量付费,减少资源浪费成本。支持阿里云抢占式实例、预留实例券(RI),进一步降低成本。
5、弹性资源:可以灵活调整集群资源,在数分钟内创建出基于云服务器 ECS、容器 ACK的集群,快速响应业务需求。
6、安全可靠:通过 VPC 和安全组设置集群网络安全策略,支持Kerberos身份认证和数据加密,使用Ranger数据访问控制。支持数据加密,保证数据安全。
阿里云E-MapReduce的产品功能
1、集群管理:方便快捷的集群管理,快速实现集群创建与扩容
- 集群创建:通过控制台页面或OpenAPI即可快速的进行多种类型的集群创建,如Hadoop、Dataflow、Datascience、Druid、ZooKeeper等开源大数据框架,无需关心底层的硬件与软件部署;
- 集群扩容:通过控制台页面或OpenAPI即可方便地增加或减少已有集群的节点数目;
- 服务配置:可以快速添加EMR提供的服务,可以监控服务的状态,并对服务组件进行配置和运维操作;
- 弹性伸缩:通过控制台界面可以方便的增加需要的组件,并进行组件的配置与运维操作;
- 动态扩容:可以设置多种弹性伸缩策略,自动地对集群计算资源进行动态的伸缩,降低TCO。
2、运维中心:完善的运维管理工具,方便快速发现和定位集群问题
- 集群监控:提供丰富的服务监控指标和主机监控指标展示,通过可视化的方式快速定位服务和主机异常;
- 事件中心:EMR服务提供丰富的事件类型,包含服务事件、管控服务事件、主机事件,可以更加快速、具体地获取到集群问题,并可以对问题发生链路进行溯源;
- 作业列表:对集群作业运行情况进行统计,快速对比异常作业,方便作业和集群性能调优;
- 诊断分析:提供HDFS冷热数据分析和小文件分析功能,对服务性能优化提供依据。
3、丰富的组件:丰富的组件支持,可以根据需要进行组件的选择
- Hadoop:支持PB级别数据存储与计算能力的大数据平台;
- Spark:基于内存的新一代分布式开源大数据框架,支持离线,实时计算,也支持 SQL 语法以及机器学习的处理;
- Hive:基于Hadoop的一套离线数据处理系统,在HDFS之上提供了结构化的表数据的管理能力,提供类 SQL 的查询语法进行数据分析处理;
- Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,具有出色的性能和可靠性;
- Flink:针对流数据和批数据的分布式处理引擎,EMR提供基于Apache Flink的商业化产品Ververica Platform构建的企业级大数据计算平台提供实时计算服务;
- Storm:实时处理计算引擎,支持毫秒级别的实时数据处理;
- ZooKeeper:分布式的,开放源码的分布式应用程序协调服务,为分布式应用提供一致性服务的软件;
- Druid:开源的实时大数据分析软件;
- Hue:方便的Web端管理工具。
4、完善的云上生态支持:对阿里云上的产品环境进行了深度的整合支持
- 支持DataWorks:为客户提供专业高效、安全可靠的一站式大数据开发与治理平台;
- 支持MaxCompute:支持阿里云的MaxCompute产品的数据的读写;
- 支持ElasticSearch:在Hadoop中内置了ES-Hadoop插件,可以直接支持ES的相关操作;
- 支持数据湖构建DLF:EMR默认支持使用DLF进行元数据管理,方便数据湖场景下元数据管理;
- 支持对象存储OSS:EMR中所有计算引擎均支持采用OSS作为存储,可以将OSS像HDFS一样使用。并采用JindoFS对OSS数据读写进行加速;
- 支持云监控:可以在云监控中设置对于EMR服务和操作的监控,方便问题快速告警;
- 支持SLS:支持将SLS作为实时数据输入源使用,提供了SDK直接操作;
- 支持阿里云的消息产品:支持如消息队列,消息服务等的读写,提供SDK包装,方便用户使用。
阿里云E-MapReduce的使用场景
E-MapReduce集群适用多种使用场景,同时支持Hadoop ecosystem和Spark能够支持的所有场景。以下示例列出了E-MapReduce使用的经典场景。
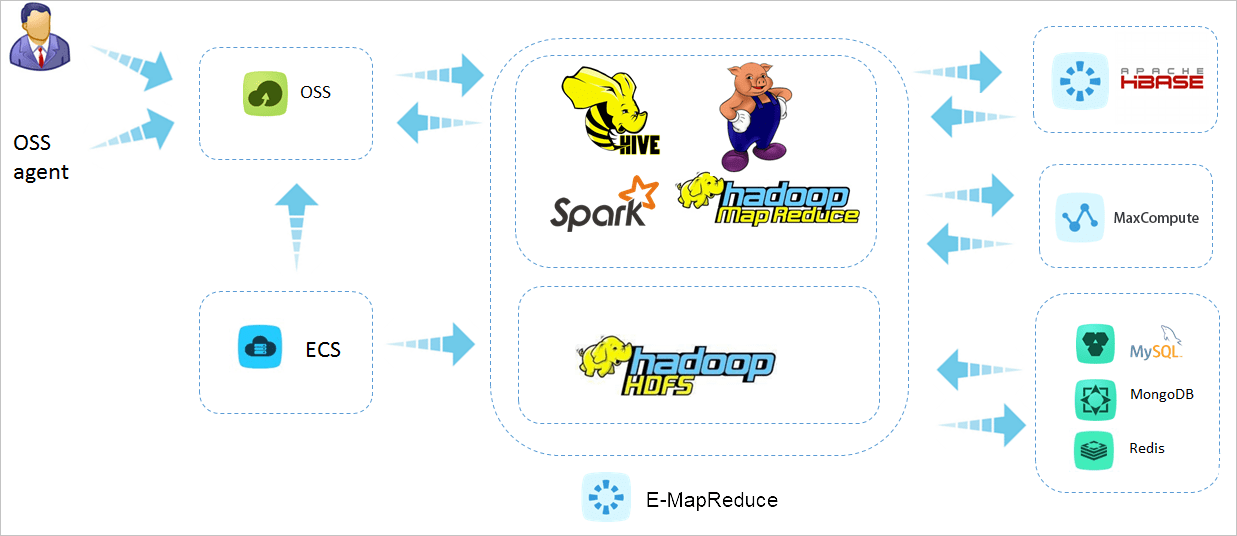
1、批量数据处理
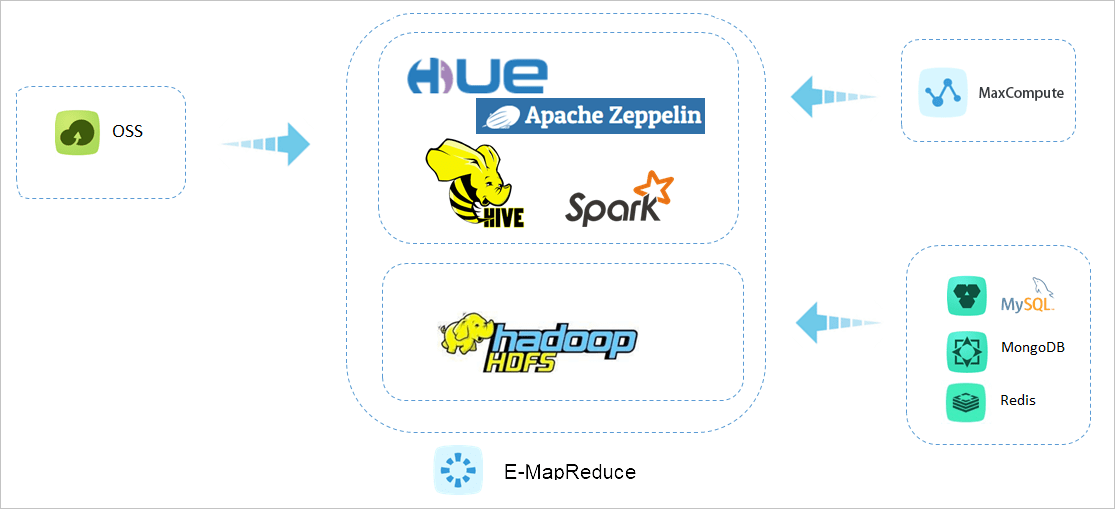
2、Ad hoc数据分析查询
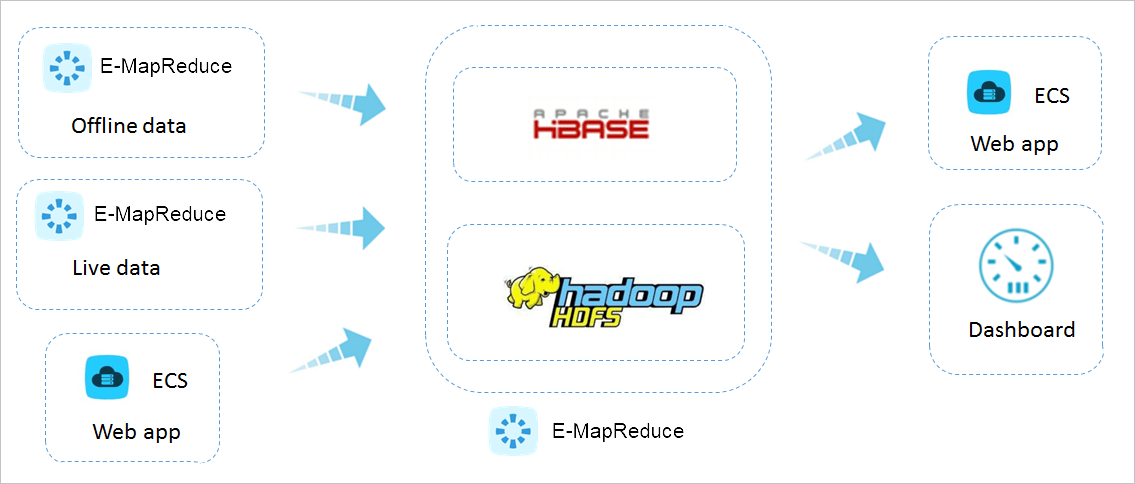
3、海量数据在线服务
4、流式数据处理
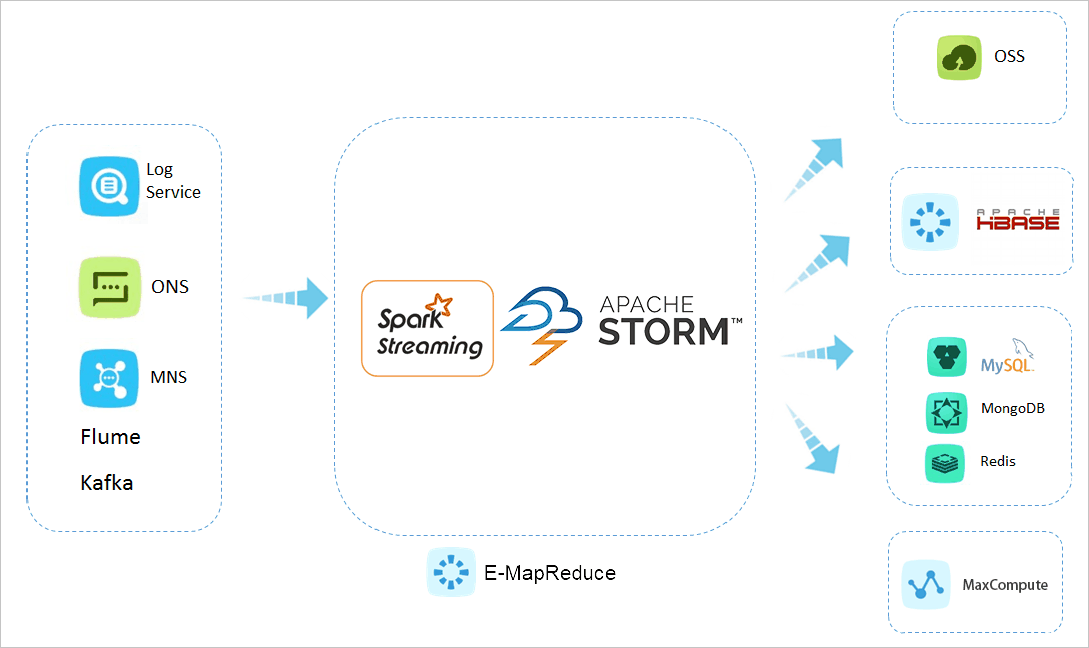
阿里云E-MapReduce的产品规格
1、Hadoop
Hadoop是完全使用开源Hadoop生态,采用YARN管理集群资源,提供Hive、Spark离线大规模分布式数据存储和计算,支持Hadoop生态圈大数据框架组件,支持OSS存储,支持Kerberos用户认证和数据加密。
2、DataScience
DataScience针对大数据+AI场景,提供了Hive、Spark离线大数据ETL,TensorFlow模型训练,用户可以选择CPU+GPU的异构计算框架,利用英伟达GPU对部分深度学习算法进行高性能计算。
3、DataFlow
阿里云提供的基于 Apache Flink 官方产品 Ververica 和 E-MapReduce Hadoop 构建的企业级大数据计算平台,完全兼容开源 Flink API,并提供额外商业增值能力。
4、ClickHouse
ClickHouse是一个面向联机分析处理(OLAP)的开源的面向列式存储的DBMS,简称CK, 与Hadoop、 Spark相比,ClickHouse很轻量级。ClickHouse支持线性扩展,简单方便,高可靠性,高容错。
以上内容整理自阿里云E-MapReduce产品页、阿里云E-MapReduce使用场景文档,如果是第一次接触建议参阅『阿里云E-MapReduce使用指南』。










 桂公网安备 45010502000016号
桂公网安备 45010502000016号